Lutter pour un avenir humain.
L'IA est sur le point de refaire le monde.
Aidez-nous à faire en sorte qu'elle profite à chacun d'entre nous.
Aidez-nous à faire en sorte qu'elle profite à chacun d'entre nous.
Tout juste annoncé
La Déclaration pour une IA pro-humaine
Une coalition bipartisane approuve les principes pro-humains pour un avenir commun de l'IA.
Aller au projet
Dernières mises à jour
Au sommaire : l'IA contre le cancer ; la proposition de moratoire sur les centres de données ; l'actualité de l'IA dans le domaine militaire ; et bien plus encore.
1 Avril, 2026
Au sommaire : le drame anthropique ; notre nouvelle campagne « Protect What's Human » (Protéger ce qui est humain) ; des simulations de jeux de guerre montrent que l'IA conduit par défaut à des résultats terrifiants ; et plus encore.
1 Mars, 2026
Au sommaire : les temps forts (et les déceptions) de Davos 2026 ; les publicités ChatGPT ; la mise à jour de l'horloge de l'apocalypse ; les électeurs de Trump veulent une réglementation de l'IA ; et plus encore.
2 Février, 2026
Des nouvelles de nous tous les mois
Rejoignez plus de 70 000 autres abonnés à notre newsletter pour recevoir chaque mois des informations sur les actions que nous menons afin de préserver notre avenir commun.
Notre mission
Orienter la technologie transformatrice
vers l'amélioration de la vie et l'éloigner des risques extrêmes à grande échelle.
vers l'amélioration de la vie et l'éloigner des risques extrêmes à grande échelle.
Nous pensons que la manière dont une technologie puissante est développée et utilisée sera le facteur le plus important pour déterminer les perspectives d'avenir de la vie. C'est pourquoi nous nous sommes donnés pour mission de veiller à ce que la technologie continue d'améliorer ces perspectives.
En savoir plus
Domaines d'intervention

Intelligence artificielle
L'IA peut être un outil incroyable qui résout des problèmes réels et accélère l'épanouissement humain, ou une force incontrôlable qui déstabilise la société, prive la plupart des gens de leurs moyens d'action, favorise le terrorisme et nous remplace.

Biotechnologie
Les progrès de la biotechnologie peuvent révolutionner la médecine, la fabrication et l'agriculture, mais en l'absence de garanties adéquates, ils augmentent également le risque de pandémies artificielles et d'armes biologiques nouvelles.

Armes nucléaires
L'utilisation pacifique de la technologie nucléaire peut contribuer à un avenir durable, mais les armes nucléaires risquent de provoquer des catastrophes massives, une escalade des conflits, un éventuel hiver nucléaire, une famine mondiale et l'effondrement d'un État.
Vidéos à l'affiche
Le meilleur contenu récent de notre part et de celle de nos partenaires :
Plus de vidéos
Projets
Découvrez quelques-uns de nos projets actuels :
Récemment annoncé

La Déclaration pour une IA pro-humaine
Une coalition bipartisane remarquable, composée d'organisations de premier plan et de personnalités éminentes, a annoncé son soutien à un ensemble de principes pro-humains destinés à guider notre avenir commun avec l'IA.
Politique et recherche
Voir tous

Promouvoir un accord mondial sur l'IA
Nous avons besoin d'une coordination internationale afin que les avantages de l'IA profitent à l'ensemble de la planète, et ne se concentrent pas uniquement dans quelques endroits. Les risques liés à l'IA avancée ne resteront pas confinés à l'intérieur des frontières, mais se propageront à l'échelle mondiale et toucheront tout le monde. Nous devons œuvrer à la mise en place d'un cadre de gouvernance international qui empêche la concentration des avantages dans quelques endroits et atténue les risques mondiaux liés à l'IA avancée.

Recommandations pour le plan d'action américain en matière d'IA
La proposition du Future of Life Institute pour le plan d'action du président Trump en matière d'IA. Nos recommandations visent à protéger la présidence contre la perte de contrôle de l'IA, à promouvoir le développement de systèmes d'IA exempts d'agendas idéologiques ou sociaux, à protéger les travailleurs américains contre la perte et le remplacement d'emplois, et plus encore.

Convergence de l'IA : risques à la croisée de l'IA et des menaces nucléaires, biologiques et cybernétiques
Le caractère à double tranchant des systèmes d'IA peut amplifier celui d'autres technologies - c'est ce que l'on appelle la convergence de l'IA. Nous fournissons une expertise politique aux décideurs américains dans trois domaines essentiels de convergence : biologique, nucléaire et cybernétique.
Promouvoir un accord mondial sur l'IA
Nous avons besoin d'une coordination internationale afin que les avantages de l'IA profitent à l'ensemble de la planète, et ne se concentrent pas uniquement dans quelques endroits. Les risques liés à l'IA avancée ne resteront pas confinés à l'intérieur des frontières, mais se propageront à l'échelle mondiale et toucheront tout le monde. Nous devons œuvrer à la mise en place d'un cadre de gouvernance international qui empêche la concentration des avantages dans quelques endroits et atténue les risques mondiaux liés à l'IA avancée.
Recommandations pour le plan d'action américain en matière d'IA
La proposition du Future of Life Institute pour le plan d'action du président Trump en matière d'IA. Nos recommandations visent à protéger la présidence contre la perte de contrôle de l'IA, à promouvoir le développement de systèmes d'IA exempts d'agendas idéologiques ou sociaux, à protéger les travailleurs américains contre la perte et le remplacement d'emplois, et plus encore.
Convergence de l'IA : risques à la croisée de l'IA et des menaces nucléaires, biologiques et cybernétiques
Le caractère à double tranchant des systèmes d'IA peut amplifier celui d'autres technologies - c'est ce que l'on appelle la convergence de l'IA. Nous fournissons une expertise politique aux décideurs américains dans trois domaines essentiels de convergence : biologique, nucléaire et cybernétique.
Avenirs
Voir tous

Le rôle de l'IA dans la transformation de la distribution du pouvoir
Les systèmes d'IA avancés sont en passe de remodeler l'économie et les rapports de pouvoir. Bien qu'ils présentent un immense potentiel de progrès et d'innovation, ils comportent aussi le risque d’une concentration extrême du pouvoir, d’inégalités inédites et de perte de contrôle. Pour que l'IA serve le bien commun, il est crucial de mettre en place des institutions résilientes, des marchés concurrentiels, ainsi que des mécanismes de redistribution robustes.

Penser des avenirs positifs où la technologie a sa place
Les récits influencent profondément nos représentations des avenirs potentiels de l'humanité avec la technologie. S'il existe bien des fictions dystopiques, les visions d'un avenir désirable se font rares. Nous cherchons à encourager la création de visions plausibles, ambitieuses et pleines d'espoir d'un avenir que nous voulons atteindre.

Les perspectives des religions traditionnelles sur des avenirs positifs avec l'IA
La majorité de la population mondiale pratique une religion traditionnelle. Pourtant, les perspectives religieuses sont généralement absentes des discussions stratégiques sur l'IA. Cette initiative vise à aider les groupes religieux à exprimer, selon leur foi, leurs préoccupations et leurs espoirs pour un monde avec l’IA, et à collaborer avec eux pour en éviter les dérives et en réaliser les promesses.
Le rôle de l'IA dans la transformation de la distribution du pouvoir
Les systèmes d'IA avancés sont en passe de remodeler l'économie et les rapports de pouvoir. Bien qu'ils présentent un immense potentiel de progrès et d'innovation, ils comportent aussi le risque d’une concentration extrême du pouvoir, d’inégalités inédites et de perte de contrôle. Pour que l'IA serve le bien commun, il est crucial de mettre en place des institutions résilientes, des marchés concurrentiels, ainsi que des mécanismes de redistribution robustes.
Penser des avenirs positifs où la technologie a sa place
Les récits influencent profondément nos représentations des avenirs potentiels de l'humanité avec la technologie. S'il existe bien des fictions dystopiques, les visions d'un avenir désirable se font rares. Nous cherchons à encourager la création de visions plausibles, ambitieuses et pleines d'espoir d'un avenir que nous voulons atteindre.
Les perspectives des religions traditionnelles sur des avenirs positifs avec l'IA
La majorité de la population mondiale pratique une religion traditionnelle. Pourtant, les perspectives religieuses sont généralement absentes des discussions stratégiques sur l'IA. Cette initiative vise à aider les groupes religieux à exprimer, selon leur foi, leurs préoccupations et leurs espoirs pour un monde avec l’IA, et à collaborer avec eux pour en éviter les dérives et en réaliser les promesses.
Communications
Voir tous

Protéger ce qui est humain
Nous mettons en place un mouvement pro-humain en faveur d'une réglementation sensée visant à garantir la sécurité et le contrôle de l'IA, en commençant par une campagne publicitaire nationale diffusée aux États-Unis.

Inversion de contrôle
Pourquoi les agents d'IA superintelligents que nous nous efforçons de créer absorberaient le pouvoir, au lieu de l'octroyer ?

Accélérateur de médias numériques
L'accélérateur de médias numériques soutient le contenu numérique de créateurs qui sensibilisent aux développements et aux problèmes actuels de l'IA et les font mieux comprendre.
Protéger ce qui est humain
Nous mettons en place un mouvement pro-humain en faveur d'une réglementation sensée visant à garantir la sécurité et le contrôle de l'IA, en commençant par une campagne publicitaire nationale diffusée aux États-Unis.
Inversion de contrôle
Pourquoi les agents d'IA superintelligents que nous nous efforçons de créer absorberaient le pouvoir, au lieu de l'octroyer ?
Accélérateur de médias numériques
L'accélérateur de médias numériques soutient le contenu numérique de créateurs qui sensibilisent aux développements et aux problèmes actuels de l'IA et les font mieux comprendre.
Octroi de subventions
Voir tous

Communauté de la sécurité existentielle de l'IA
Une communauté dédiée à la sécurité du développement de l'IA, comprenant à la fois des professeurs et des chercheurs en IA. Les membres sont invités à assister aux réunions, à participer à une communauté en ligne et à demander une aide financière pour leurs déplacements.

Bourses d'études
Depuis 2021, nous proposons des bourses de doctorat et de postdoctorat en sécurité existentielle de l'IA technique. En 2024, nous avons lancé une bourse de doctorat sur la gouvernance de l'IA entre les États-Unis et la Chine.

Appels d'offres, concours et collaborations
Demandes de propositions (RFP), concours publics et subventions de collaboration en soutien direct aux projets et initiatives internes de FLI .
Communauté de la sécurité existentielle de l'IA
Une communauté dédiée à la sécurité du développement de l'IA, comprenant à la fois des professeurs et des chercheurs en IA. Les membres sont invités à assister aux réunions, à participer à une communauté en ligne et à demander une aide financière pour leurs déplacements.
Bourses d'études
Depuis 2021, nous proposons des bourses de doctorat et de postdoctorat en sécurité existentielle de l'IA technique. En 2024, nous avons lancé une bourse de doctorat sur la gouvernance de l'IA entre les États-Unis et la Chine.
Appels d'offres, concours et collaborations
Demandes de propositions (RFP), concours publics et subventions de collaboration en soutien direct aux projets et initiatives internes de FLI .
Bulletin d'information
Des mises à jour régulières sur les technologies qui façonnent notre monde
Chaque mois, nous proposons à plus de 70 000 abonnés les dernières actualités sur la manière dont les technologies émergentes transforment notre monde. Cette publication comprend un résumé des principales évolutions dans nos domaines d'intérêt, ainsi que les informations clés concernant nos activités.
Abonnez-vous à notre lettre d'information pour recevoir ces points forts à la fin de chaque mois.
Éditions récentes
Au sommaire : l'IA contre le cancer ; la proposition de moratoire sur les centres de données ; l'actualité de l'IA dans le domaine militaire ; et bien plus encore.
1 Avril, 2026
Au sommaire : le drame anthropique ; notre nouvelle campagne « Protect What's Human » (Protéger ce qui est humain) ; des simulations de jeux de guerre montrent que l'IA conduit par défaut à des résultats terrifiants ; et plus encore.
1 Mars, 2026
Au sommaire : les temps forts (et les déceptions) de Davos 2026 ; les publicités ChatGPT ; la mise à jour de l'horloge de l'apocalypse ; les électeurs de Trump veulent une réglementation de l'IA ; et plus encore.
2 Février, 2026
Au sommaire : notre indice de sécurité IA pour l'hiver 2025 ; la nouvelle loi sur la sécurité IA de New York ; le décret présidentiel américain sur l'IA ; les résultats de notre concours « Keep the Future Human » ; et bien plus encore !
31 Décembre, 2025
Voir tous
Dernier contenu
Le contenu le plus récent que nous avons publié :

Contenu à la une
Ce que l'IA peut et ne peut pas faire pour guérir le cancer
Un nouvel essai d'Emilia Javorsky, docteure en médecine, titulaire d'une maîtrise en santé publique et directrice du programme Futures
Les dirigeants du secteur technologique ont promis que l'IA permettrait de vaincre le cancer. La réalité est plus complexe — et plus porteuse d'espoir. Cet essai examine les domaines dans lesquels l'IA contribue réellement à faire progresser la recherche sur le cancer, ceux où les promesses ne se concrétisent pas, ainsi que les mesures que les chercheurs, les décideurs politiques et les bailleurs de fonds doivent prendre à présent.
Lire l'essai ->Articles

Des scientifiques de renom, des chefs religieux, des responsables politiques et des artistes appellent à l'interdiction de la superintelligence, alors qu'un sondage révèle que les Américains n'en veulent pas
Parmi les premiers signataires figurent les pionniers de l'IA Yoshua Bengio et Geoffrey Hinton, les personnalités médiatiques de premier plan Steve Bannon et Glenn Beck, la conseillère à la sécurité nationale de Barack Obama, Susan Rice, les pionniers du monde des affaires Steve Wozniak et Richard Branson, cinq lauréats du prix Nobel, l'ancienne présidente irlandaise Mary Robinson, les acteurs Stephen Fry et Joseph Gordon-Levitt, ainsi que des centaines d'autres personnalités.
27 Mars, 2026
Déclaration : Responsable de la politique américaine concernant les recommandations législatives de la Maison Blanche en matière d'IA
La Maison Blanche a publié vendredi ses recommandations législatives tant attendues sur l'IA, et celles-ci continuent d'appeler le Congrès à […]
22 Mars, 2026

Le gouverneur DeSantis demande aux agences de l'État de Floride de s'associer au Future of Life Institute protéger les familles contre les dangers de l'IA.
Cette collaboration permettra d'élaborer un programme de formation pour les conseillers en situation de crise et un formulaire de signalement des dangers liés à l'IA à l'échelle de l'État, ciblant les applications d'IA dangereuses.
9 Mars, 2026
« Voilà ce que signifie être pro-humain », déclare une large coalition regroupant des groupes conservateurs, progressistes et de la société civile dans une déclaration de principes communs sur l'IA
Alors que la controverse autour des excès de la Silicon Valley ne cesse de s'amplifier, un groupe remarquablement diversifié, représentant l'ensemble du spectre politique, a annoncé une série de principes relatifs à l'intelligence artificielle visant à définir clairement les objectifs de ce mouvement émergent en faveur de l'humain.
4 Mars, 2026
Voir tous
Podcasts
Disponible sur toutes les plateformes de podcast :

-
Dernières nouvelles
Défense en profondeur : stratégies multicouches contre les risques liés à l'IA (avec Li-Lian Ang)
2 Avril, 2026


Utilisez votre voix
Protégez l'humain.
Les géants de la tech s'affrontent pour développer des systèmes d'intelligence artificielle de plus en plus puissants et incontrôlables, conçus pour remplacer les humains. Vous avez le pouvoir d'agir.
Agissez dès maintenant pour protéger notre avenir :
Agir ->
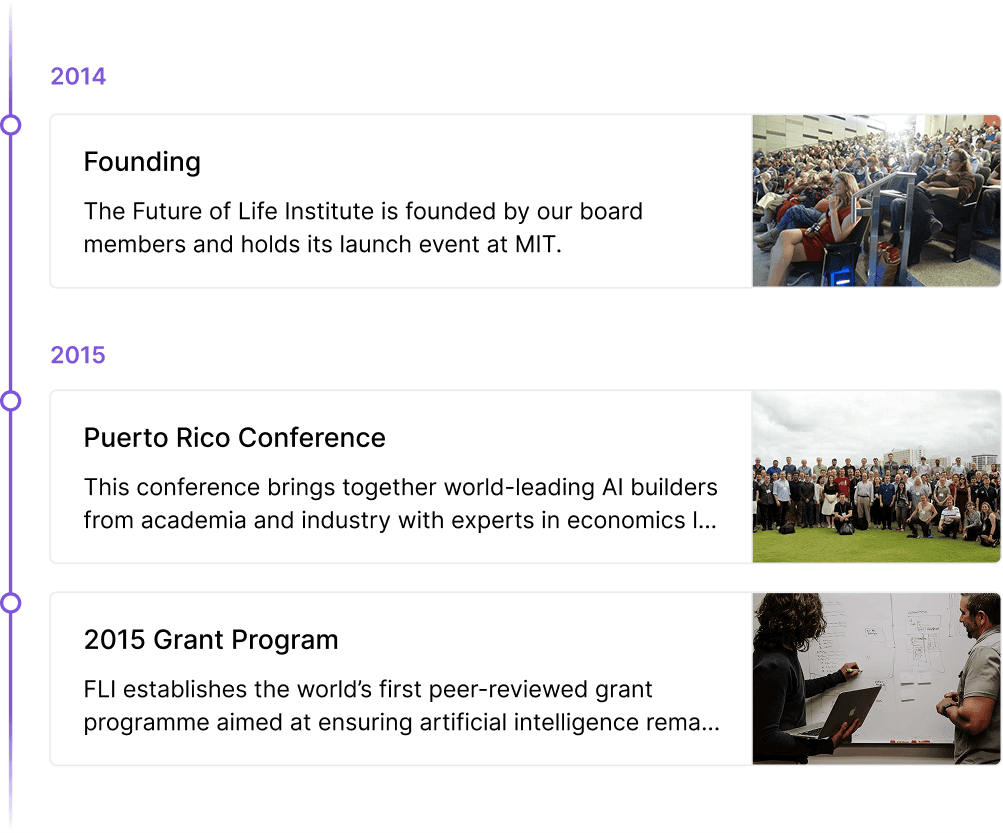
Notre histoire
Depuis 2014, nous nous efforçons de préserver l'avenir de l'humanité.
Découvrez le travail et les réalisations de la FLIdepuis sa création, notamment les conférences historiques, les programmes de subventions et les lettres ouvertes qui ont influencé le cours de la technologie.