Kämpfen für eine menschliche Zukunft.
KI wird die Welt verändern.
Helfen Sie uns, dafür zu sorgen, dass wir alle davon profitieren.
Helfen Sie uns, dafür zu sorgen, dass wir alle davon profitieren.
Gerade angekündigt
Die Pro-Human-KI-Erklärung
Überparteiliche Koalition befürwortet menschenfreundliche Grundsätze für eine gemeinsame KI-Zukunft.
Zum Projekt gehen
Aktuelle Updates von uns
Darunter: KI im Kampf gegen Krebs; vorgeschlagenes Moratorium für Rechenzentren; Neuigkeiten zur KI im Militärbereich; und vieles mehr.
1 April, 2026
Unter anderem: Anthropisches Drama; unsere neue Kampagne „Protect What's Human“ (Schütze das Menschliche); Kriegsspielsimulationen zeigen, dass KI zu erschreckenden Ergebnissen führt; und vieles mehr.
1 März, 2026
Unter anderem: Höhepunkte (und Enttäuschungen) von Davos 2026; ChatGPT-Werbung; Update zur Doomsday Clock; Trump-Wähler wollen KI-Regulierung; und mehr.
2 Februar, 2026
Hören Sie jeden Monat von uns
Schließen Sie sich mehr als 70.000 anderen Newsletter-Abonnenten an und erhalten Sie monatliche Updates zu unserer Arbeit für eine gesicherte gemeinsame Zukunft.
Unsere Mission
Steuerung der transformativen Technologie
zum Nutzen des Lebens und weg von extremen Risiken im großen Maßstab.
zum Nutzen des Lebens und weg von extremen Risiken im großen Maßstab.
Wir glauben, der wichtigste Faktor für die Zukunftsaussichten des Lebens wird die Herangehensweise sein, mit der transformative Technologien entwickelt und eingesetzt werden. Deshalb haben wir es uns zur Aufgabe gemacht, dafür zu sorgen, dass sich diese Aussichten weiter verbessern.
Mehr erfahren
Schwerpunktbereiche

Künstliche Intelligenz
KI kann ein unglaubliches Werkzeug sein, das echte Probleme löst und das menschliche Wohlergehen beschleunigt, oder eine unkontrollierbare Kraft, die die Gesellschaft destabilisiert, die meisten Menschen entmündigt, Terrorismus ermöglicht und uns ersetzt.

Biotechnologie
Fortschritte in der Biotechnologie können die Medizin, die Produktion und die Landwirtschaft revolutionieren, aber ohne angemessene Sicherheitsvorkehrungen erhöhen sie auch das Risiko von künstlich erzeugten Pandemien und neuartigen biologischen Waffen.

Atomwaffen
Die friedliche Nutzung der Nukleartechnologie kann zu einer nachhaltigen Zukunft beitragen, aber Atomwaffen bergen die Gefahr einer Massenkatastrophe, einer Eskalation von Konflikten, eines nuklearen Winters, einer weltweiten Hungersnot und eines Staatszerfalls.
Ausgewählte Videos
Die besten aktuellen Inhalte von uns und unseren Partnern:
Mehr Videos
Ausgewählte Projekte
Informieren Sie sich über einige unserer aktuellen Projekte:
Kürzlich angekündigt

Die Pro-Human-KI-Erklärung
Eine bemerkenswerte überparteiliche Koalition führender Organisationen und prominenter Persönlichkeiten hat ihre Unterstützung für eine Reihe von Pro-Human-Prinzipien angekündigt, die als Leitlinien für unsere gemeinsame Zukunft mit KI dienen sollen.
Politik und Forschung
Alle anzeigen

Förderung eines globalen KI-Abkommens
Wir brauchen internationale Koordination, damit die Vorteile der KI weltweit zum Tragen kommen und sich nicht nur auf wenige Orte konzentrieren. Die Risiken fortschrittlicher KI bleiben nicht innerhalb der Landesgrenzen, sondern verbreiten sich weltweit und betreffen alle Menschen. Wir sollten auf einen internationalen Regulierungsrahmen hinarbeiten, der eine Konzentration der Vorteile auf wenige Orte verhindert und die globalen Risiken fortschrittlicher KI mindert.

Empfehlungen für den AI-Aktionsplan der USA
Der Vorschlag des Future of Life Institute für den KI-Aktionsplan von Präsident Trump. Unsere Empfehlungen zielen darauf ab, die Präsidentschaft vor dem Kontrollverlust über KI zu schützen, die Entwicklung von KI-Systemen frei von ideologischen oder sozialen Agenden zu fördern, amerikanische Arbeitnehmer vor Arbeitsplatzverlust und Ersatz zu schützen und vieles mehr.

KI-Konvergenz: Risiken am Schnittpunkt von KI zu nuklearen, biologischen und Cyber-Bedrohungen
Das Gefahrenpotenzial von KI-Systemen kann die Gefahrenpotenziale anderer Technologien verstärken – dies wird als KI-Konvergenz bezeichnet. Wir bieten politischen Entscheidungsträgern in den Vereinigten Staaten politische Expertise in drei wichtigen Konvergenzbereichen: Bio-, Nuklear- und Cybertechnologien.
Förderung eines globalen KI-Abkommens
Wir brauchen internationale Koordination, damit die Vorteile der KI weltweit zum Tragen kommen und sich nicht nur auf wenige Orte konzentrieren. Die Risiken fortschrittlicher KI bleiben nicht innerhalb der Landesgrenzen, sondern verbreiten sich weltweit und betreffen alle Menschen. Wir sollten auf einen internationalen Regulierungsrahmen hinarbeiten, der eine Konzentration der Vorteile auf wenige Orte verhindert und die globalen Risiken fortschrittlicher KI mindert.
Empfehlungen für den AI-Aktionsplan der USA
Der Vorschlag des Future of Life Institute für den KI-Aktionsplan von Präsident Trump. Unsere Empfehlungen zielen darauf ab, die Präsidentschaft vor dem Kontrollverlust über KI zu schützen, die Entwicklung von KI-Systemen frei von ideologischen oder sozialen Agenden zu fördern, amerikanische Arbeitnehmer vor Arbeitsplatzverlust und Ersatz zu schützen und vieles mehr.
KI-Konvergenz: Risiken am Schnittpunkt von KI zu nuklearen, biologischen und Cyber-Bedrohungen
Das Gefahrenpotenzial von KI-Systemen kann die Gefahrenpotenziale anderer Technologien verstärken – dies wird als KI-Konvergenz bezeichnet. Wir bieten politischen Entscheidungsträgern in den Vereinigten Staaten politische Expertise in drei wichtigen Konvergenzbereichen: Bio-, Nuklear- und Cybertechnologien.
Zukunftsvisionen
Alle anzeigen

Die Rolle von KI bei der Umverteilung von Macht
Hochentwickelte KI-Systeme werden die Wirtschaft und die Machtstrukturen in der Gesellschaft umgestalten. Sie bieten ein enormes Potenzial für Fortschritt und Innovation, bergen aber auch die Gefahr konzentrierter Kontrolle, nie dagewesener Ungleichheit und Entmündigung. Um sicherzustellen, dass KI dem Gemeinwohl dient, müssen wir widerstandsfähige Institutionen, wettbewerbsfähige Märkte und Systeme aufbauen, die die Vorteile breit verteilen.

Positive Zukunftsvisionen mit Technologie
Storytelling hat einen signifikanten Einfluss auf die Überzeugungen und Vorstellungen der Menschen über die mögliche Zukunft der Menschheit mit Technologie. Zwar warnen viele Erzählungen vor Dystopien, aber positive Zukunftsvisionen sind Mangelware. Wir versuchen Anreize für die Schaffung plausibler, erstrebenswerter und hoffnungsvoller Visionen einer Zukunft schaffen, die wir anstreben wollen.

Religiöse Perspektiven auf eine positive KI-Zukunft
Der Großteil der Weltbevölkerung gehört einer Religion an. Dennoch sind die Perspektiven dieser Religionen in den strategischen Diskussionen über künstliche Intelligenz weitgehend abwesend. Diese Initiative zielt darauf ab, religiöse Gruppen dabei zu unterstützen, ihre glaubensspezifischen Bedenken und Hoffnungen für eine Welt mit KI zu äußern und mit ihnen zusammenzuarbeiten, um Schäden abzuwenden und Vorteile zu realisieren.
Die Rolle von KI bei der Umverteilung von Macht
Hochentwickelte KI-Systeme werden die Wirtschaft und die Machtstrukturen in der Gesellschaft umgestalten. Sie bieten ein enormes Potenzial für Fortschritt und Innovation, bergen aber auch die Gefahr konzentrierter Kontrolle, nie dagewesener Ungleichheit und Entmündigung. Um sicherzustellen, dass KI dem Gemeinwohl dient, müssen wir widerstandsfähige Institutionen, wettbewerbsfähige Märkte und Systeme aufbauen, die die Vorteile breit verteilen.
Positive Zukunftsvisionen mit Technologie
Storytelling hat einen signifikanten Einfluss auf die Überzeugungen und Vorstellungen der Menschen über die mögliche Zukunft der Menschheit mit Technologie. Zwar warnen viele Erzählungen vor Dystopien, aber positive Zukunftsvisionen sind Mangelware. Wir versuchen Anreize für die Schaffung plausibler, erstrebenswerter und hoffnungsvoller Visionen einer Zukunft schaffen, die wir anstreben wollen.
Religiöse Perspektiven auf eine positive KI-Zukunft
Der Großteil der Weltbevölkerung gehört einer Religion an. Dennoch sind die Perspektiven dieser Religionen in den strategischen Diskussionen über künstliche Intelligenz weitgehend abwesend. Diese Initiative zielt darauf ab, religiöse Gruppen dabei zu unterstützen, ihre glaubensspezifischen Bedenken und Hoffnungen für eine Welt mit KI zu äußern und mit ihnen zusammenzuarbeiten, um Schäden abzuwenden und Vorteile zu realisieren.
Kommunikation
Alle anzeigen

Schütze das Menschliche
Wir bauen eine menschenfreundliche Bewegung für eine vernünftige Regulierung auf, um KI sicher und unter unserer Kontrolle zu halten. Den Auftakt bildet eine nationale Werbekampagne, die in den USA ausgestrahlt wird.

Kontrolle Umkehrung
Warum die superintelligenten KI-Agenten, die wir erschaffen wollen, Macht absorbieren, statt sie zu gewähren | Die neueste Studie von Anthony Aguirre.

Digital Media Accelerator
Der Digital Media Accelerator unterstützt digitale Inhalte von Urhebern, die das Bewusstsein und das Verständnis für aktuelle KI-Entwicklungen und -Themen fördern.
Schütze das Menschliche
Wir bauen eine menschenfreundliche Bewegung für eine vernünftige Regulierung auf, um KI sicher und unter unserer Kontrolle zu halten. Den Auftakt bildet eine nationale Werbekampagne, die in den USA ausgestrahlt wird.
Kontrolle Umkehrung
Warum die superintelligenten KI-Agenten, die wir erschaffen wollen, Macht absorbieren, statt sie zu gewähren | Die neueste Studie von Anthony Aguirre.
Digital Media Accelerator
Der Digital Media Accelerator unterstützt digitale Inhalte von Urhebern, die das Bewusstsein und das Verständnis für aktuelle KI-Entwicklungen und -Themen fördern.
Vergabe von Förderung
Alle anzeigen

KI-Community für Existenzielle Sicherheit
Eine Gemeinschaft, die sich dafür einsetzt, dass KI sicher entwickelt wird, und der sowohl Lehrkräfte als auch KI-Forscher angehören. Die Mitglieder sind eingeladen, an Sitzungen teilzunehmen, sich an einer Online-Community zu beteiligen und Reiseunterstützung zu beantragen.

Stipendien
Seit 2021 bieten wir Doktoranden- und Postdoktorandenstipendien für technische KI-Existenzsicherheit an. Im Jahr 2024 haben wir ein Doktorandenstipendium zum Thema "US-China AI Governance" eingerichtet.

RFPs, Wettbewerbe und Kooperationen
Aufforderungen zur Einreichung von Vorschlägen (RFP), öffentliche Wettbewerbe und Kooperationszuschüsse zur direkten Unterstützung von internen Projekten und Initiativen FLI .
KI-Community für Existenzielle Sicherheit
Eine Gemeinschaft, die sich dafür einsetzt, dass KI sicher entwickelt wird, und der sowohl Lehrkräfte als auch KI-Forscher angehören. Die Mitglieder sind eingeladen, an Sitzungen teilzunehmen, sich an einer Online-Community zu beteiligen und Reiseunterstützung zu beantragen.
Stipendien
Seit 2021 bieten wir Doktoranden- und Postdoktorandenstipendien für technische KI-Existenzsicherheit an. Im Jahr 2024 haben wir ein Doktorandenstipendium zum Thema "US-China AI Governance" eingerichtet.
RFPs, Wettbewerbe und Kooperationen
Aufforderungen zur Einreichung von Vorschlägen (RFP), öffentliche Wettbewerbe und Kooperationszuschüsse zur direkten Unterstützung von internen Projekten und Initiativen FLI .
Newsletter
Regelmäßige Updates zu den Technologien, die unsere Welt verändern
Jeden Monat versorgen wir mehr als 70.000 Abonnenten mit den neuesten Nachrichten darüber, wie neue Technologien unsere Welt verändern. Der Newsletter enthält eine Zusammenfassung der wichtigsten Entwicklungen in unseren Schwerpunktbereichen sowie aktuelle Informationen zu unserer Arbeit.
Abonnieren Sie unseren Newsletter, um diese Highlights am Ende eines jeden Monats zu erhalten.
Neuere Ausgaben
Darunter: KI im Kampf gegen Krebs; vorgeschlagenes Moratorium für Rechenzentren; Neuigkeiten zur KI im Militärbereich; und vieles mehr.
1 April, 2026
Unter anderem: Anthropisches Drama; unsere neue Kampagne „Protect What's Human“ (Schütze das Menschliche); Kriegsspielsimulationen zeigen, dass KI zu erschreckenden Ergebnissen führt; und vieles mehr.
1 März, 2026
Unter anderem: Höhepunkte (und Enttäuschungen) von Davos 2026; ChatGPT-Werbung; Update zur Doomsday Clock; Trump-Wähler wollen KI-Regulierung; und mehr.
2 Februar, 2026
Darunter: unser KI-Sicherheitsindex für den Winter 2025, das neue KI-Sicherheitsgesetz von New York, die KI-Verordnung des Weißen Hauses, die Ergebnisse unseres Wettbewerbs „Keep the Future Human“ und vieles mehr!
31 Dezember, 2025
Alle anzeigen
Neuester Inhalt
Die neuesten Inhalte, die wir veröffentlicht haben:

Ausgewählter Inhalt
Wie KI Krebs heilen kann – und wie nicht
Ein neuer Aufsatz von Dr. med. Emilia Javorsky, MPH, Leiterin des Futures-Programms
Führungskräfte aus der Tech-Branche haben versprochen, dass KI Krebs heilen wird. Die Realität ist komplexer – und gibt Anlass zu größerer Hoffnung. Dieser Aufsatz untersucht, in welchen Bereichen KI die Krebsforschung tatsächlich vorantreibt, wo die Versprechen hinter den Erwartungen zurückbleiben und was Forscher, politische Entscheidungsträger und Geldgeber als Nächstes tun müssen.
Lesen Sie den Aufsatz ->Beiträge

Prominente Wissenschaftler, Glaubensführer, Politiker und Künstler fordern ein Verbot von Superintelligenz, da Umfragen zeigen, dass die Amerikaner diese nicht wollen
Zu den Erstunterzeichnern zählen die KI-Pioniere Yoshua Bengio und Geoffrey Hinton, die bekannten Medienpersönlichkeiten Steve Bannon und Glenn Beck, Obamas nationale Sicherheitsberaterin Susan Rice, die Wirtschaftsvorreiter Steve Wozniak und Richard Branson, fünf Nobelpreisträger, die ehemalige irische Präsidentin Mary Robinson, die Schauspieler Stephen Fry und Joseph Gordon-Levitt sowie Hunderte weitere.
27 März, 2026
Stellungnahme: Leiter der US-Politik zu den Gesetzesempfehlungen des Weißen Hauses zur KI
Das Weiße Haus hat am Freitag seine lang erwarteten Empfehlungen zur KI-Gesetzgebung veröffentlicht, in denen es den Kongress weiterhin dazu auffordert, […]
22 März, 2026

Gouverneur DeSantis weist Behörden des Bundesstaates Florida an, mit Future of Life Institute zusammenzuarbeiten Future of Life Institute Familien vor den Gefahren der KI zu schützen
Im Rahmen der Zusammenarbeit werden ein Schulungsprogramm für Krisenberater und ein landesweites Formular zur Meldung von Schäden durch KI entwickelt, das auf gefährliche KI-Begleit-Apps abzielt.
9 März, 2026
„Das bedeutet es, sich für den Menschen einzusetzen“, erklärt eine breite Koalition aus konservativen, progressiven und zivilgesellschaftlichen Gruppen in einer gemeinsamen Grundsatzerklärung zur KI
Angesichts der zunehmenden Kritik an den Übergriffen des Silicon Valley hat eine bemerkenswert vielfältige Gruppe aus dem gesamten politischen Spektrum eine Reihe von KI-Grundsätzen verkündet, um die Ziele der aufkommenden menschenorientierten Bewegung klar zu definieren.
4 März, 2026
Alle anzeigen

Forschungsapiere


Benutze deine Stimme
Beschütze das Menschliche
Große Technologieunternehmen sind dabei, immer leistungsfähigere, unkontrollierbare KI-Systeme zu entwickeln, die menschliche Arbeitskraft ersetzen sollen. Sie haben die Möglichkeit, etwas dagegen zu tun.
Werden Sie heute aktiv, um unsere Zukunft zu schützen:
Maßnahmen ergreifen ->
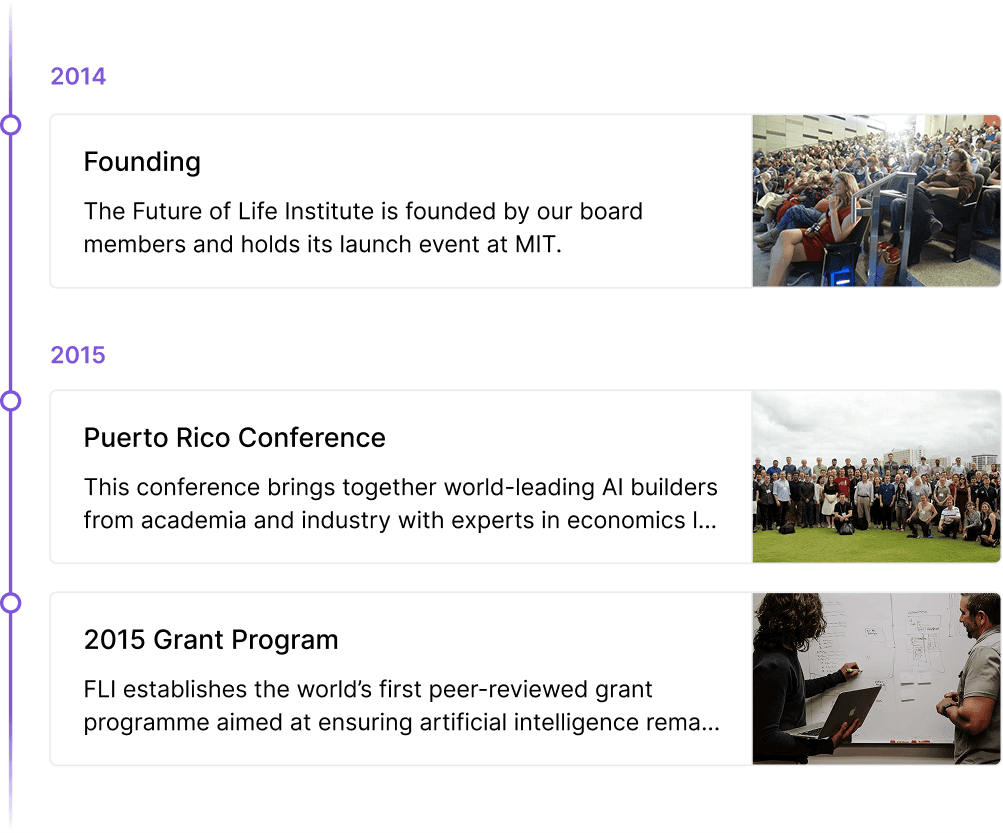
Unsere Geschichte
Seit 2014 arbeiten wir daran, die Zukunft der Menschheit zu sichern.
Erfahren Sie mehr über die Arbeit und die Erfolge des FLIseit seiner Gründung, einschließlich historischer Konferenzen, Zuschussprogramme und offener Briefe, die die Entwicklung der Technologie geprägt haben.