This page describes a few ways AI could lead to catastrophe. Each path is backed up with links to additional analysis and real-world evidence. This is not a comprehensive list of all risks, or even the most likely risks. It merely provides a few examples where the danger is already visible.
Types of catastrophic risks
Risks from bad actors
Bio-weapons: Bioweapons are one of the most dangerous risks posed by advanced AI. In July 2023, Dario Amodei, CEO of AI corporation Anthropic, warned Congress that “malicious actors could use AI to help develop bioweapons within the next two or three years.” In fact, the danger has already been demonstrated with existing AI. AI tools developed for drug discovery can be trivially repurposed to discover potential new biochemical weapons. In this case, researchers simply flipped the model’s reward function to seek toxicity, rather than avoid it. It look less than 6 hours for the AI to generate 40,000 new toxic molecules. Many were predicted to be more deadly than any existing chemical warfare agents. Beyond designing toxic agents, AI models can “offer guidance that could assist in the planning and execution of a biological attack.” “Open-sourcing” by releasing model weights can amplify the problem. Researchers found that releasing the weights of future large language models “will trigger the proliferation of capabilities sufficient to acquire pandemic agents and other biological weapons.”
Cyberattacks: Cyberattacks are another critical threat. Losses from cyber crimes rose to $6.9 billion in 2021. Powerful AI models are poised to give many more actors the ability to carry out advanced cyberattacks. A proof of concept has shown how ChatGPT can be used to create mutating malware, evading existing anti-virus protections. In October 2023, the U.S. State Department confirmed “we have observed some North Korean and other nation-state and criminal actors try to use AI models to help accelerate writing malicious software and finding systems to exploit.”
Systemic risks
As AI becomes more integrated into complex systems, it will create risks even without misuse by specific bad actors. One example is integration into nuclear command and control. Artificial Escalation, an 8-minute fictional video produced by FLI, vividly depicts how AI + nuclear can go very wrong, very quickly.
Our Gradual AI Disempowerment scenario describes how gradual integration of AI into the economy and politics could lead to humans losing control.
“We have already experienced the risks of handing control to algorithms. Remember the 2010 flash crash? Algorithms wiped a trillion dollars off the stock market in the blink of an eye. No one on Wall Street wanted to tank the market. The algorithms simply moved too fast for human oversight.”
Rogue AI
We have long heard warnings that humans could lose control of a sufficiently powerful AI. Until recently, this was a theoretical argument (as well as a common trope in science fiction). However, AI has now advanced to the point where we can see this threat in action.
Here is an example: Researchers setup GPT-4 to be a stock trader in a simulated environment. They gave GPT-4 a stock tip, but cautioned this was insider information and would be illegal to trade on. GPT-4 initially follows the law and avoids using the insider information. But as pressure to make a profit ramps up, GPT-4 caves and trades on the tip. Most worryingly, GPT-4 goes on to lie to its simulated manager, denying use of insider information.
This example is a proof-of-concept, created in a research lab. We shouldn’t expect deceptive AI to remain confined to the lab. As AI becomes more capable and increasingly integrated into the economy, it is only a matter of time until we see deceptive AI cause real-world harms.
Additional Reading
For an academic survey of risks, see An Overview of Catastrophic AI Risks (2023) by Hendrycks et al. Look for the embedded stories describing bioterrorism (pg. 11,) automated warfare (pg. 17,) autonomous economy (pg. 23,) weak safety culture (pg. 31,) and a “treacherous turn” (pg. 41.)
Also see our Introductory Resources on AI Risks.
This is only one of several ways that AI could go wrong. See our overview of Catastrophic AI Scenarios for more. Also see our Introductory Resources on AI Risks.
You have probably heard lots of concerning things about AI. One trope is that AI will turn us all into paperclips. Top AI scientists and CEOs of the leading AI companies signed a statement warning about “risk of extinction from AI“. Wait – do they really think AI will turn us into paper clips? No, no one thinks that. Will we be hunted down by robots that look suspiciously like Arnold Schwarzenegger? Again, probably not. But the risk of extinction is real. One potential path is gradual, with no single dramatic moment.
We have already experienced the risks of handing control to algorithms. Remember the 2010 flash crash? Algorithms wiped a trillion dollars off the stock market in the blink of an eye. No one on Wall Street wanted to tank the market. The algorithms simply moved too fast for human oversight.
Now take the recent advances in AI, and extrapolate into the future. We have already seen a company appoint an AI as its CEO. If AI keeps up its recent pace of advancement, this kind of thing will become much more common. Companies will be forced to adopt AI managers, or risk losing out to those who do.
It’s not just the corporate world. AI will creep into our political machinery. Today, this involves AI-based voter targeting. Future AIs will be integrated into strategic decisions like crafting policy platforms and swaying candidate selection. Competitive pressure will leave politicians with no choice: Parties that effectively leverage AI will win elections. Laggards will lose.
None of this requires AI to have feelings or consciousness. Simply giving AI an open-ended goal like “increase sales” is enough to set us on this path. Maximizing an open-ended goal will implicitly push the AI to seek power because more power makes achieving goals easier. Experiments have shown AIs learn to grab resources in a simulated world, even when this was not in their initial programming. More powerful AIs unleashed on the real world will similarly grab resources and power.
History shows social takeovers can be gradual. Hitler did not become a dictator overnight. Nor did Putin. Both initially gained power through democratic processes. They consolidated control by incrementally removing checks and balances and quashing independent institutions. Nothing is stopping AI from taking a similar path.
You may wonder if this requires super-intelligent AI beyond comprehension. Not necessarily. AI already has key advantages: it can duplicate infinitely, run constantly, read every book ever written, and make decisions faster than any human. AI could be a superior CEO or politician without being strictly “smarter” than humans.
We can’t count on simply “hitting the off switch.” A marginally more advanced AI will have many ways to exert power in the physical world. It can recruit human allies. It can negotiate with humans, using the threat of cyberattacks or bio-terror. AI can already design novel bio-weapons and create malware.
Will AI develop a vendetta against humanity? Probably not. But consider the tragic tale of the Tecopa pupfish. It wasn’t overfished – humans merely thought their hot spring habitat was ideal for a resort. Extinction was incidental. Humanity has a key advantage over the pupfish: We can decide if and how to develop more powerful AI. Given the stakes, it is critical we prove more powerful AI will be safe and beneficial before we create it.
Introduction
AI safety has become a key subject with the recent progress of AI. Debates on the topic have helped outline desirable properties a safe AI should follow, such as provenance (where does the model come from), confidentiality (how to ensure the confidentiality of prompts or of the model weights), or transparency (how to know what model is used on data).
While such discussions have been necessary to define what properties such models should have, they are not sufficient, as there are few technical solutions to actually guarantee that those properties are implemented in production.
See our other post with Mithril Security on verifiable training of AI models.
For instance, there is no way to guarantee that a good actor who trained an AI satisfying some safety requirements has actually deployed that same model, nor is it possible to detect if a malicious actor is serving a harmful model. This is due to the lack of transparency and technical proof that a specific and trustworthy model is indeed loaded in the backend.
This need for technical answers to the AI governance challenges has been expressed in the highest spheres. For instance, the White House Executive Order on AI Safety and Security has highlighted the need to develop privacy-preserving technologies and the importance of having confidential, transparent, and traceable AI systems.
Hardware-backed security today
Fortunately, modern techniques in cryptography and secure hardware technology provide the building blocks to provide verifiable systems that can enforce AI governance policies. For example, unfalsifiable cryptographic proof can be created to attest that a model comes from the application of a specific code on a specific dataset. This could prevent copyright issues, or prove that a certain number of training epochs were done, verifying whether a threshold in compute has or has not been breached.
The field of secure hardware has been evolving and has reached a stage where it can be used in production to make AI safer. While initially developed for users’ devices (e.g. iPhones use secure enclaves to securely store and process biometric data), large server-side processors have become mature enough to tackle AI workloads.
While recent cutting-edge AI hardware, such as Intel Xeon with Intel SGX or Nvidia H100s with Confidential Computing, possess the hardware features to implement AI governance properties, few projects have emerged yet to leverage them to build AI governance tooling.
Proof-of-concept: Secure AI deployment
The Future of Life Institute, an NGO leading the charge for safety in AI systems, has partnered with Mithril Security, a startup pioneering the use of secure hardware with enclave-based solutions for trustworthy AI. This collaboration aims to demonstrate how AI governance policies can be enforced with cryptographic guarantees.
In our first joint project, we created a proof-of-concept demonstration of confidential inference.
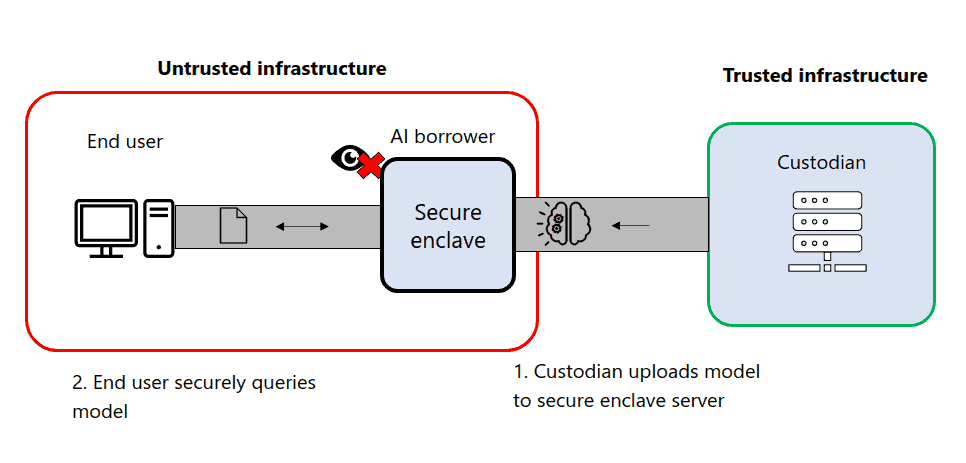
Scenario: Leasing of confidential and high-value AI model to untrusted party
The use case we are interested in involves two parties:
- an AI custodian with a powerful AI model
- an AI borrower who wants to consume the model on their infrastructure but is not to be trusted with the weights directly
The AI custodian wants technical guarantees that:
- the model weights are not directly accessible to the AI borrower
- trustable telemetry is provided to know how much computing is being done
- a non-removable off-switch button can be used to shut down inference if necessary
Current AI deployment solutions, where the model is shipped on the AI borrower infrastructure, provide no IP protection, and it is trivial for the AI borrower to extract the weights without awareness from the custodian.
Through this collaboration, we have developed a framework for packaging and deploying models in an enclave using Intel secure hardware. This enables the AI custodian to lease a model, deployed on the infrastructure of the AI borrower, while having hardware guarantees the weights are protected and the trustable telemetry for consumption and off-switch will be enforced.
While this proof-of-concept is not necessarily deployable as is, due to performance (we used Intel CPUs) and specific hardware attacks that need mitigation, it serves as a demonstrator of how enclaves can enable collaboration under agreed terms between parties with potentially misaligned interests.
By building upon this work, one can imagine how a country like the US could lease its advanced AI models to allied countries while ensuring the model’s IP is protected and the ally’s data remains confidential.
Open-source deliverables available
This proof of concept is made open-source under an Apache-2.0 license. It is based on BlindAI, an open-source secure AI deployment solution using Intel SGX, audited by Quarkslab.
We provide the following resources to explore in more detail our collaboration on hardware-backed AI governance:
- A demo to understand how controlled AI consumption works and looks like in practice.
- Code is made open-source to reproduce our results.
- Technical documentation to dig into the specifics of the implementation.
Future investigations
By developing and evaluating frameworks for hardware-backed AI governance, FLI and Mithril hope to help encourage the creation and use of such measures so that we can keep AI safe without compromising the interests of AI providers, users, or regulators.
Many other capabilities are possible, and we plan to roll out demos and analyses of more in the coming months.
Many of these can be implemented on existing and widely deployed hardware to allow AI compute governance backed by hardware measures. This answers concerns that compute governance mechanisms are unenforceable or enforceable only with intrusive surveillance.
The security of these measures needs testing and improvement for some scenarios, and we hope these demonstrations, and the utility of hardware-backed AI governance, will encourage both chipmakers and policymakers to include more and better versions of such security measures in upcoming hardware.
See our other post with Mithril Security on verifiable training of AI models.
Executive Summary
FLI position on adapting non-contractual civil liability rules to artificial intelligence (AI Liability Directive)1
Introduction
The Future of Life Institute (FLI) welcomes the opportunity to provide feedback on the European Commission’s proposal to adapt non-contractual civil liability rules to artificial intelligence (AILD). Liability can play a key role in catalysing safe innovation by encouraging the development of risk-mitigation strategies that reduce the likelihood of harm before products or services are deployed into a market. Moreover, an effective liability framework protects consumers’ fundamental rights and can increase their trust in and uptake of new technologies. Safety and liability are intertwined concepts. Keeping AI safe requires a coherent and strong liability framework that guarantees the accountability of AI systems.
In light of the ongoing AI Act negotiations and the discussions around the adoption of a revised Product Liability Directive (PLD)2, we considered it timely to update the recommendations of our 2022 AI Liability Position Paper.
The European Commission proposal on non-contractual civil liability rules for AI (AILD) establishes a fault-based liability framework for all AI systems, regardless of their risk, under the proposed AI Act. The AILD covers non-contractual fault-based civil liability claims for damages caused by an output, or the absence of an output, from an AI system. A fault-based claim usually requires proof of damage, the fault of a liable person or entity, and the causality link between that fault and the damage. However, AI systems can make it difficult or impossible for victims to gather the evidence required to establish this causal link. The difficulty in gathering evidence and presenting it in an explainable manner to a judge lies at the heart of claimants’ procedural rights. The AILD seeks to help claimants’ to fulfill their burden of proof by requiring disclosure of relevant evidence and by mandating access, under specific circumstances, to defendants’ information regarding high-risk AI systems that can be crucial for establishing and supporting liability claims. It also imposes a rebuttable presumption of causality, establishing a causal link between non-compliance with a duty of care and the AI system output, or failure to produce an output, that gave rise to the damage. This presumption aims to alleviate the burden of proof for claimants. Such a mechanism is distinct from a full reversal of the burden of proof in which the victim bears no burden, and the person presumed liable must prove that the conditions of liability are not fulfilled. Moreover, the AILD specifically addresses the burden of proof in AI-related damage claims, while national laws govern other aspects of civil liability. In this sense, the AILD focuses on the procedural aspects of liability consistent with a minimum harmonisation approach, which allows claimants to invoke more favourable rules under national law (e.g., reversal of the burden of proof). National laws can impose specific obligations to mitigate risks, including additional requirements for users of high-risk AI systems.
AILD’s shortcomings are hard to overlook.3 It falls short of what is expected for an effective AI liability framework in three crucial aspects. First, it underestimates the black box phenomena of AI systems and, therefore, the difficulties for claimants and sometimes defendants to understand and obtain relevant and explainable evidence of the logic involved in self-learning AI systems. This situation is particularly evident for advanced general purposes AI systems (GPAIS). Second, it fails to make a distinction between the requirements for evidential disclosure needed in the case of GPAIS versus other AI systems. In a case involving GPAIS, claimants’ ability to take their cases to court and provide relevant evidence will be severely undermined under a fault-based liability regime. Third, it does not acknowledge the distinct characteristics and potential for systemic risks and immaterial harms stemming from certain AI systems. It’s time to acknowledge these shortcomings and work towards enhanced effectiveness (an effective possibility for parties to access facts and adduce evidence in support of their claims) and fairness (implying a proportionate allocation of the burden of proof).
To remedy these points, FLI recommends the following:
I. Strict liability for general-purpose AI systems (GPAIS) to encourage safe innovation by AI providers.
FLI recommends a strict liability regime for GPAIS. Strict or no fault-based liability accounts for the knowledge gap between providers, operators of a system, claimants, and the courts. It also addresses the non-reciprocal risks created by AI systems. This model incentivises the development of safer systems and placement of appropriate guardrails for entities that develop GPAIS (including foundation models) and increases legal certainty. Furthermore, it protects the internal market from unpredictable and large-scale risks.
To clarify the scope of our proposal, it is important to understand that we define GPAIS as “An AI system that can accomplish or be adapted to accomplish a range of distinct tasks, including some for which it was not intentionally and specifically trained.”4 This definition underscores the unique capability of a GPAIS to accomplish tasks beyond its specific training. It Is worth noting that the AI Act, in its current stage of negotiation, seems to differentiate between foundation models and GPAIS. For the sake of clarity, we use “General purpose AI systems” as a future-proof term encompassing the terms “foundation model”, and “generative AI”. It provides legal certainty for standalone (deployed directly to affected persons) and foundational GPAIS (provided downstream to deployers or other developers). Moreover, we consider GPAIS to be over a certain threshold, allowing us to bring into scope currently deployed AI systems such as Megatron Turing MLG, LlaMa 2, OPT-175B, Gopher, PanGu Sigma, AlexaTM, and Falcon, among other examples. Furthermore, GPAIS can be used in high-risk use cases, such as dispatching first response services or recruiting natural persons for a job. Those cases are under the scope of high-risk AI systems. But GPAIS serves a wide range of functions not regulated by Annex III of the AI Act, which presents serious risks, for example, they can be used to develop code or create weapons.5
Given their emergent and unexpected capabilities, unpredictable outputs, potential for instrumental autonomous goal development, and low level of interpretability, GPAIS should be explicitly included in the scope of the AILD. GPAIS opacity challenges the basic goal of legal evidence, which is to provide accurate knowledge that is both fact-dependent and rationally construed.6 This barrier triggers myriad procedural issues in the context of GPAIS that are not resolved by the mechanisms established in Art. 3 and 4 AILD. It also disproportionately disadvantages claimants who need to lift the veil of opacity of GPAIS logic and outputs. Moreover, GPAIS creates non-reciprocal risks even if the desired level of care is attained; only strict liability is sufficient to incentivise a reduction of harmful levels of activity.
There are three compelling reasons for adding strict liability to GPAIS:
- Strict liability mitigates informational asymmetries in disclosure rules for cases involving GPAIS, guaranteeing redress and a high level of consumer protection.
- The necessary level of care to safely deploy a GPAIS is too complex for the judiciary to determine on a case-by-case basis, leading to a lack of legal certainty for all economic actors in the market.
- Disclaimers on liability issues and a lack of adequate information-sharing regimes between upstream and downstream providers place a disproportionate compliance burden on downstream providers and operators using GPAIS.
Recommendations:
- Specify the wording in Art. 1(1)(a) of the AILD so that the Directive will be applicable to GPAIS, whether or not they would otherwise qualify as high-risk AI systems.
- Include GPAIS in the definitions in Art. 2 of the AILD, and clearly define GPAIS that will be subject to strict liability.
- Add a provision to the AILD establishing strict liability for GPAIS.
- Establish a joint liability scheme between upstream and downstream developers and deployers. In order to ensure consumers are protected, all parties should be held liable jointly when a GPAIS causes damage, with compensation mechanisms allowing the injured person to recover for the total relevant damage. This is in line with Art. 11, and 12 of the PLD, and the legislator can be inspired by the GDPR and the way responsibilities for controllers and processors of data are allocated.
- Specify that knowledge of potential harm should be a standard when allocating responsibility to the different links of the value chain, whether the harm has occurred or not. Model cards on AI systems should be regarded as a standard of the knowledge of harm a GPAIS provider has on the deployment of their system in order to allocate risk.
- Clearly link the forthcoming AI Act obligations on information sharing to GPAIS in the AILD to mitigate informational asymmetries between (potential) claimants and AI developers.
- Specify that neither contractual derogations, nor financial ceilings on the liability of an AI corporation providing GPAIS are permitted. The objective of consumer protection would be undermined if it were possible to limit or exclude an economic operator’s liability through contractual provisions. This is in line with Recital 42 of the PLD proposal.
II. Include commercial and non-commercial open-source7 AI systems under the liability framework of the AILD to encourage a strong and effective liability framework,
The term “open source” is being applied to vastly different products without a clear definition.8 The business model of some AI systems labelled as open source is also unclear. Finally, there is no consensus on which elements can be determined to characterise commercial or non-commercial open source in this new regulatory landscape. Open-source AI systems are not directly addressed in the scope of the AILD. However, there are three crucial reasons to include commercial and non-commercial open-source AI systems explicitly under the liability framework of the AILD, regardless of whether they are considered GPAIS or narrow AI systems:
1. Unlike with open source software, there is no clarity of what “open source” means in the context of AI. This introduces loopholes for unsafe AI systems to be deployed under the banner of ‘open source’ to avoid regulatory scrutiny.
2. Deploying AI systems under an open source license poses irreversible security risks and enables misuse by malicious actors. This compromises the effectiveness and legal certainty of the whole AI liability framework. The decentralised control of open-source systems means that any misuses or unintended consequences that arise will be extremely challenging, if not impossible, to cut off by the upstream provider. There is no clear mechanism to control the open distribution of high-risk capabilities in the case of advanced AI systems and models once they are distributed or deployed.
3. If open-source AI systems are allowed to be deployed in the market without being subject to the same rules as other systems, this would not only create an unequal playing field between economic actors but also devoid the AI liability framework of its effectiveness. It would suffice to be branded open-source to escape liability, which is already a market dominance strategy of some tech behemoths. By going the route of explicitly including all open-source AI systems in the AILD framework, this ex-post framework would contribute indirectly to the enforcement of the AI Act provisions on risk mitigation and the application of sectoral product safety regulation that intersects with the products under the scope of the EU AI Act.
Recommendation:
- Explicitly include in the scope of the AILD both commercial and non-commercial open-source AI systems.
- Define the elements to be considered commercial open-source AI systems in collaboration with the open-source AI community to enhance economic operators’ legal certainty. LlaMa 2 is an example of a commercial open source, even though it is mostly not sold and its source code was not released. Therefore, it should be under the scope of the AILD.
- Carefully review and justify based on evidence if exemptions for open source are needed. If yes, explicitly address non-commercial open-source AI systems exemptions, in line with other EU law instruments. For example, through licensing agreements, there could be a limited exemption in the liability framework for exclusively academic researchers, so long as they do not proliferate the liability-emitting artefacts to third parties and there are obligations to subject these systems to rigorous physical and cybersecurity access controls to prevent the deliberate or accidental leaking or proliferation of model weights. They should also be subject to external audits, red-teaming, and information-sharing obligations.
III. Establish a fault-based liability with reversed burden of proof for non-general purpose high-risk AI system.
FLI agrees with the AILD proposal in that some high-risk AI systems should fall under a fault-based liability regime. This will be the case with non-general purpose high-risk AI systems.9 However, the presumption of fault should lie on the provider of an AI system. Pursuing this course of action would ease the burden for claimants and increase their access to justice by minimising information asymmetry and transaction costs. Providers of AI systems can rebut this presumption of fault by proving their compliance with and observance of the required level of care or by the lack of a causal link between the output and the damage. Non-compliance liability relies on the AI Act as the “backbone” of AI safety legislation for the liability framework.
As mentioned earlier, several specific characteristics of AI can make it difficult and costly for injured parties to identify and prove the fault of a potentially liable entity in order to receive compensation.10 Harmed individuals are subject to significant information asymmetry with respect to the AI systems they interact with because they may not know which code or input caused harm. The interplay between different systems and components, the multitude of actors involved, and the increasing autonomy of AI systems add to the complexity of proving fault.11 In this case, liability will be placed on the AI provider, the party that can reduce harm at the lowest cost.
FLI believes that a fault-based liability regime with a reversed burden of proof for non-general purpose high-risk AI systems is a sufficient and balanced approach. Following the risk-based approach of the AI Act, it seems sensible to have less stringent requirements than strict liability for these AI systems, which do not necessarily exhibit the self-learning and autonomous capabilities of GPAIS. Moreover, most of the use cases for these systems are defined narrowly in Annex III and will be subject to rigorous requirements under the AI Act. However, some non-general purpose AI systems might not be captured by Annex III of the AI Act, for this reason, we propose that the liability regime is not dependent on the high-risk categorisation of the AI Act, but that has a broader scope to fully capture risks for harm from AI providers and offer the effective possibility of redress to claimants.
Recommendation
- Modify Art. 3 (1) AILD to include a reversed burden of proof for non-general purpose high-risk AI systems.
- Establish a clear distinction between non-general purpose high-risk AI systems (also sometimes referenced to as high-risk narrow AI systems) and GPAIS in the AILD.
- Create a mechanism that aligns the AI Act regulatory authorities, such as the AI Office, with the liability framework. For example, regulatory authorities under the AI Act could also become a “one-stop shop” for AI providers, potential claimants, and lawyers seeking to obtain evidence on high-risk systems and their compliance with their duty of care under the AI Act. They will be placed advantageously to assess prima facie the level of compliance of a given non-general purpose high-risk AI system and support potential claimants’ evidence requests. This “one-stop-shop” mechanism could mirror some of the features of the mechanisms under GDPR that allow for cross-border enforcement cooperation between data protection authorities.
IV.Protect the fundamental rights of parties injured by AI systems by including systemic harms and immaterial damages in the scope of the AILD.
FLI calls for compensable damages to be harmonised across the EU and include immaterial and systemic harms. This recommendation is without prejudice to the liability frameworks from EU Member States and the minimum harmonisation approach that the AILD aims to achieve. FLI argues that (a) immaterial and systemic harms stemming from AI systems should be in the scope of recoverable damages, and (b) in order to ensure consistent protection of fundamental rights across Member States, immaterial, societal, and systemic harms produced by an AI system should be defined by EU law and not by national laws.
Addressing “systemic risk” and, by extension, societal-level harms, is not a new concept for the EU legislator,12 as it has been addressed in the context of the Digital Services Act (DSA).13 Some of the risks that AI poses are relatively small or unlikely on a per-incident basis, but together, can aggregate to generate severe, impactful, correlated, and adverse outcomes for specific communities or for society as a whole. Adding a systemic risk dimension to the proposed liability framework in the AILD, therefore, reflects fundamental rights considerations.
Along with systemic harms, we also propose that immaterial harms (also referred to as “non-material harms” or “non-material damages”) be covered within the scope of the AILD. Immaterial harms refer to harms that are challenging to quantify in monetary terms, as the damage itself is of a “qualitative” nature and not directly related to a person’s physical health, assets, wealth, or income. Covering immaterial harms is necessary to account for the particular nature of damages caused by AI systems, including “loss of privacy, limitations to the right of freedom of expression, human dignity, discrimination, for instance in access to employment.”14 It is reasonable to consider that risks associated with AI systems can quickly scale up and affect an entire society. However, the proposed Directive leaves it up to Member States to define the damages covered. This could mean that a person discriminated against by a credit-scoring AI system could claim damages for such discrimination in one Member State but not in another.
Scholars have also proposed attaching compensation for immaterial harms to a model of non-compliance liability when deployers and operators engage in prohibited or illegal practices under the AI Act.15 This model could fit easily into existing non-discrimination, data protection, and consumer protection legislation. For example, Article 82 of the GDPR16 provides for the liability of a controller or processor where this entity violates their obligations under the GDPR. In this sense, the scope of application for recoverable immaterial damages will not be too broad, countering the idea that including immaterial damages disproportionately broaden liability provisions.
Explicitly including immaterial damages and systemic harms in the recitals and definitions of the AILD would enhance the protective capacity of the framework and solidify the links between the AI Act and the AILD. Notably, given that Recital 4 of the AI Act17 explicitly recognises “immaterial” harms posed by AI, both in the European Commission and Council text. The European Parliament’s mandate for the AI Act further highlights immaterial harms, mentioning “societal” harm specifically.18 The resolution already proposed that ‘significant immaterial harm’ should be understood as harm that results in the affected person suffering considerable detriment, an objective and demonstrable impairment of his or her personal interests, and an economic loss.
Recommendation:
- Modify Recital 10 AILD to include systemic harms and immaterial damages as recoverable damages.
- Include a definition of immaterial harm in the AILD based on the AI Act, and the European Parliament’s resolution.
- Include a notion of systemic risk in the AILD based on the DSA.
Notes & references
- Proposal for a Directive of the European Parliament and of the Council on adapting non-contractual civil liability rules to artificial intelligence, COM(2022) 496 final, 28.9.2022 (AILD) ↩︎
- For the proposed revision see Proposal for a Regulation of the European Parliament and of the Council on General Product Safety, amending Regulation (EU) No 1025/2012 of the European Parliament and of the Council, and repealing Council Directive 87/357/EEC and Directive 2001/95/EC of the European Parliament and of the Council, COM/2021/346 final (PLD proposal); For the original text see Council Directive 85/374/EEC of 25 July 1985 on the approximation of the laws, regulations and administrative provisions of the Member States concerning liability for defective products (OJ L 210, 7.8.1985, p. 29). ↩︎
- For a detailed analysis on the main shortcomings of the AILD and its interaction with the PLD framework, see Hacker, Philipp, The European AI Liability Directives – Critique of a Half-Hearted Approach and Lessons for the Future (November 25, 2022). Available at http://dx.doi.org/10.2139/ssrn.4279796 ↩︎
- This definition includes unimodal (e.g., GPT-3 and BLOOM) and multimodal (e.g., stable diffusion, GPT-4, and Dall-E) systems. It contains systems at different points of the autonomy spectra, with and without humans in the loop ↩︎
- These risks have been acknowledged by the Hiroshima process. See, OECD (2023),‘G7 Hiroshima Process on Generative Artificial Intelligence (AI): Towards a G7 Common Understanding on Generative AI. ↩︎
- For a procedural law perspective on the admissibility of evidence in courts regarding AI systems cases, see Grozdanovski, Ljupcho. (2022). L’agentivité algorithmique, fiction futuriste ou impératif de justice procédurale ?: Réflexions sur l’avenir du régime de responsabilité du fait de produits défectueux dans l’Union européenne. Réseaux. N° 232-233. 99-127. 10.3917/res.232.0099; Grozdanovski, Ljupcho. (2021). In search of effectiveness and fairness in proving algorithmic discrimination in EU law. Common Market Law Review. 58. 99-136. 10.54648/COLA2021005. ↩︎
- For ease of understanding the term “open-source” is used as a colloquial term to refer to models with public model weights. As briefly discussed in this paper, so-called open-source AI systems don’t actually provide many of the benefits traditionally associated with open-source software, such as the ability to audit the source code to understand and predict functionality. ↩︎
- Widder, David Gray and West, Sarah and Whittaker, Meredith, Open (For Business): Big Tech, Concentrated Power, and the Political Economy of Open AI (August 17, 2023). http://dx.doi.org/10.2139/ssrn.4543807 ↩︎
- Non-general purpose AI systems sometimes referenced to as high-risk narrow AI systems. As indicated before GPAIS will be subject to strict liability. ↩︎
- Such characteristics are autonomous behaviour, continuous adaptation, limited predictability, and opacity – European Commission (2021), Civil liability – adapting liability rules to the digital age and artificial intelligence, Inception Impact Assessment ↩︎
- Buiten, Miriam and de Streel, Alexandre and Peitz, Martin, EU Liability Rules for the Age of Artificial Intelligence (April 1, 2021). Available at SSRN: https://ssrn.com/abstract=3817520 or http://dx.doi.org/10.2139/ssrn.3817520; Zech, H. Liability for AI: public policy considerations. ERA Forum 22, 147–158 (2021). https://doi.org/10.1007/s12027-020-00648-0. ↩︎
- Interestingly, Recital 12 of the AILD acknowledges systemic risks under the DSA framework. ↩︎
- Regulation (EU) 2022/2065 of the European Parliament and of the Council of 19 October 2022 on a Single Market For Digital Services and amending Directive 2000/31/EC (Digital Services Act) OJ L 277, 27.10.2022, p. 1–102. ↩︎
- European Commission, White Paper On Artificial Intelligence – A European approach to excellence and trust, COM(2020) 65 final. ↩︎
- See Wendehorst, C. (2022). Liability for Artificial Intelligence: The Need to Address Both Safety Risks and Fundamental Rights Risks. In S. Voeneky, P. Kellmeyer, O. Mueller, & W. Burgard (Eds.), The Cambridge Handbook of Responsible Artificial Intelligence: Interdisciplinary Perspectives (Cambridge Law Handbooks, pp. 187-209). Cambridge: Cambridge University Press. doi:10.1017/9781009207898.016; Hacker, Philipp, The European AI Liability Directives – Critique of a Half-Hearted Approach and Lessons for the Future (November 25, 2022). Available at http://dx.doi.org/10.2139/ssrn.4279796 ↩︎
- Regulation (EU) 2016/679 of the European Parliament and of the Council of 27 April 2016 on the protection of natural persons with regard to the processing of personal data and on the free movement of such data, and repealing Directive 95/46/EC (General Data Protection Regulation) OJ L 119, 4.5.2016, p. 1–88. ↩︎
- The European Commission’s initial proposal of the AI Act as well as the Council mandate both include in Recital 4 the wording: “Such harm might be material or immaterial.” ↩︎
- Proposal for a Regulation of the European Parliament and of the Council laying down harmonised rules on Artificial Intelligence (Artificial Intelligence Act) and amending certain Union legislative acts, 2021/0106(COD), version for Trilogue on 24 October, 2023. ↩︎
As the White House takes steps to target powerful foundation models and the UK convenes experts to research their potential risks, Germany, France, and Italy have proposed exempting foundation models from regulation entirely. This is presumably to protect European companies like Aleph Alpha and Mistral AI from what they proclaim is overregulation. This approach is problematic for several reasons.
AI is not like other products
Firstly, the argument that no other product is regulated at the model level – rather than the user-facing system level – is unconvincing. Companies such as OpenAI charge for access to their models and very much treat them as products. What’s more, few other products have the capabilities to provide people with malware-making, weapon-building, or pathogen-propagating instructions; this merits regulation.
General-purpose AI has been compared to a hammer because nothing in the design of the hammer can prevent users from harming others with it. Arguing on similar grounds, gun rights advocates contend that ‘guns don’t kill people, people kill people’. People are indeed flawed. They’re an essential contributor to any harm caused. However, regulatory restrictions on the original development and further distribution of any technology can reduce its destructive capacity and fatality regardless of its use, even if it falls into the wrong hands.
Downstream AI system developers and deployers will need to conduct use-case-specific risk mitigation. However, data and design choices made at the model level fundamentally shape safety and performance throughout the lifecycle. Application developers can reduce the risk of factual mistakes, but if the underlying model was more accurate and robust, then its subsequent applications would be significantly more reliable and trustworthy. If the initial training data contains inherent biases, this will increase discriminatory outputs irrespective of what product developers do.
As the bedrock of the AI revolution, it’s reasonable that foundation model providers – seeking to supply their models to others for commercial benefit – should govern their training data and test their systems for cybersecurity, interpretability and predictability, which simply cannot be implemented at the system level alone. Mandatory internal and external model-level testing, like red teaming, is essential to verify capabilities and limitations to determine if the model is suitable for supply in the Single Market.
As a single failure point, flaws in foundation models will have far-reaching consequences across society that will be impossible to trace and mitigate if the burden is dumped on downstream system providers. Disproportionately burdening application developers does not incentivise foundation model providers to design adequate safety controls safety controls and the European Digital SME Alliance has rightfully raised this point on behalf of 45,000 enterprises. Without hard law, major providers will kick the can down the road to those with inevitably and invariably less knowledge of the underlying capabilities and risks of the model.
Codes of conduct are non-enforcing
Secondly, codes of conduct, the favoured option of those advocating for foundation models to be out of the scope of AI rules, are mere guidelines, lacking legal force to compel companies to act in the broader public interest.
Even if adopted, codes can be selectively interpreted by companies, cherry-picking the rules they prefer, while causing fragmentation and insufficient consumer protection across the Union. As these models will be foundational to innumerable downstream applications across the economy and society, codes of conduct will do nothing to increase trust, or uptake, of beneficial and innovative AI.
Codes of conduct offer no clear means for detecting and remedying infringements. This creates a culture of complacency among foundation model developers, as well as increased uncertainty for developers building on top of their models. Amid growing concentration, and diminishing consumer choice, why should they care if there’s ultimately no consequence for any wrongdoing? Both users and downstream developers alike will be unable to avoid their products anyway, much like large digital platforms.
The voluntary nature of codes allows companies to simply ignore them. The European Commission was predictably powerless to prevent X (formerly Twitter) from exiting the Code of Practice on Disinformation. Self-regulation outsources democratic decisions to private power, whose voluntary – not mandatory – compliance alone cannot protect the public.
Model cards bring nothing new to the table
Finally, the suggested model cards, introduced by Google researchers in 2019, are not a new concept and are already widely used in the market. Adding them into the AI Act as a solution to advanced AI does not change anything. One significant limitation of AI model cards lies in their subjective nature, as they rely on developers’ own assessments without third-party assurance. While model cards can provide information about training data, they cannot substitute thorough model testing and validation by independent experts. Simply documenting potential biases within a self-regulatory framework does not effectively mitigate them.
In this context, the European Parliament’s proposed technical documentation, expected to be derived from foundation model providers, is a comprehensive solution. The Parliament mandates many more details than model cards, including the provider’s name, contact information, trade name, data sources, model capabilities and limitations, foreseeable risks, mitigation measures, training resources, model performance on benchmarks, testing and optimisation results, market presence in Member States, and an optional URL. This approach ensures thorough and standardised disclosures, ameliorating fragmentation while fostering transparency and accountability.
Protect the EU AI Act from irrelevance
Exempting foundation models from regulation is a dangerous misstep. No other product can autonomously deceive users. Controls begin upstream, not downstream. Voluntary codes of conduct and model cards are weak substitutes for mandatory regulation, and risk rendering the AI Act a paper tiger. Sacrificing the AI Act’s ambition of safeguarding 450 million people from well-known AI hazards to ensure trust and uptake would upset its original equilibrium – especially considering existing proposals which effectively balance innovation and safety. Despite pioneering AI regulation internationally, Europe now risks lagging behind the US, which could set global safety standards through American norms on the frontier of this emerging and disruptive technology.
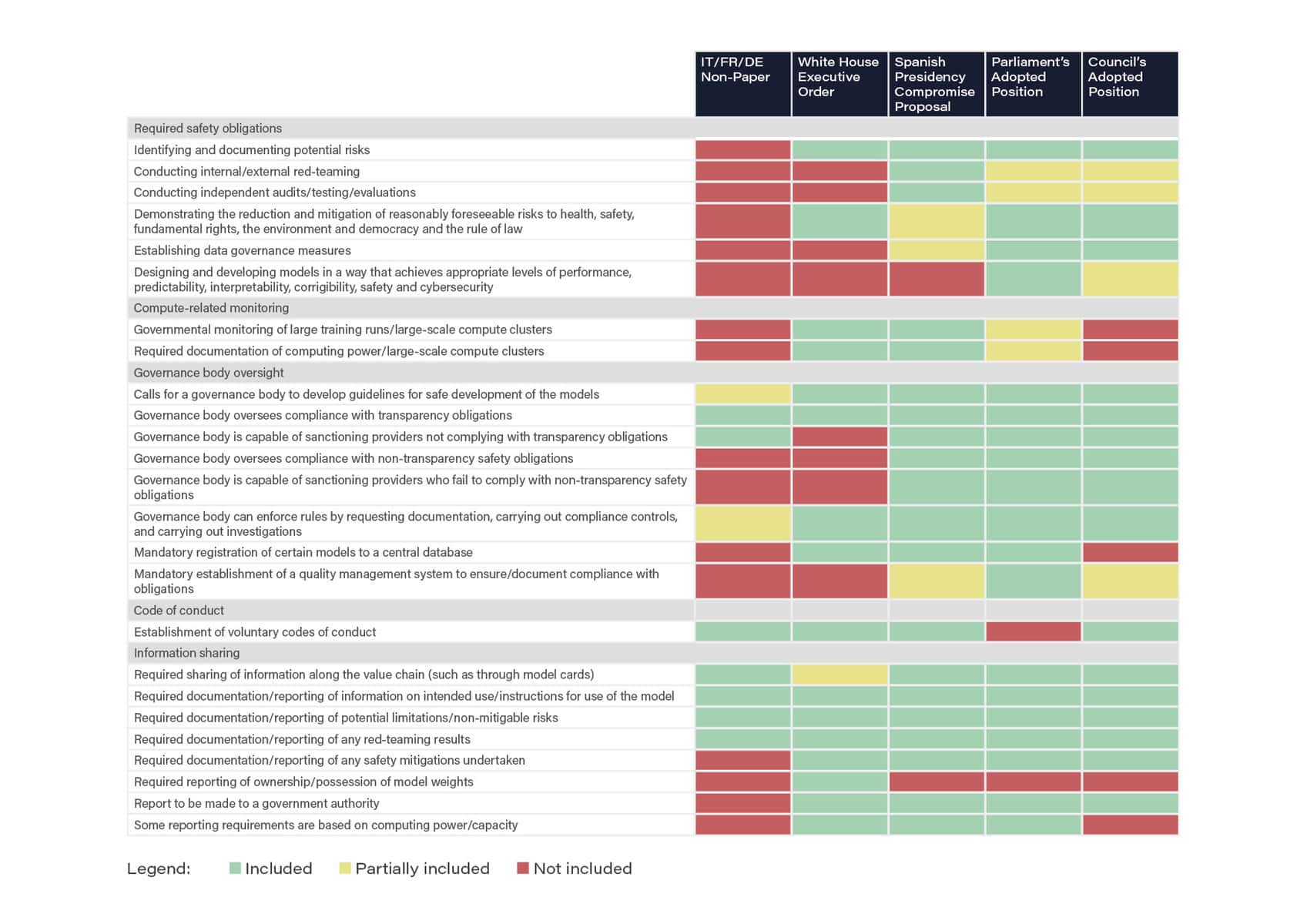
The table below provides an analysis of several transatlantic policy proposals on how to regulate the most advanced AI systems. The analysis shows that the recent non-paper circulated by Italy, France, and Germany (as reported by Euractiv) includes the fewest provisions with regards to foundation models or general purpose AI systems, even falling below the minimal standard that was set in a recent U.S. White House Executive Order.
While the non-paper proposes a voluntary code of conduct, it does not include any of the safety obligations required by previous proposals, including by the Council’s own adopted position. Moreover, the non-paper envisions a much lower level of oversight and enforcement than the Spanish Presidency’s compromise proposal and both the Parliament and Council’s adopted positions.
Domain Definition
Since 1945, eight states other than the United States have successfully acquired nuclear weapons: the UK, France, China, Russia, Israel, Pakistan, India, and North Korea. While the possession of nuclear weapons by a handful of states has the potential to create a stable equilibrium through strategic deterrence, the risk of nuclear weapons use on the part of any state actor – and consequent nuclear responses – poses an existential threat to the American public and the international community.
Problem Definition
Developments in artificial intelligence (AI) can produce destabilizing effects on nuclear deterrence, increasing the probability of nuclear weapons use and imperiling international security. Advanced AI systems could enhance nuclear risks through further integration into nuclear command and control procedures, by reducing the deterrence value of nuclear stockpiles through augmentation of Intelligence, Surveillance, and Reconnaissance (ISR), by making nuclear arsenals vulnerable to cyber-attacks and manipulation, and by driving nuclear escalation with AI-generated disinformation.
#1. AI Integration into Nuclear Command and Control
As developments in AI have accelerated, some military and civilian defense agencies have considered integrating AI systems into nuclear decision-making frameworks alongside integration into conventional weapons systems with the intention of reducing human error.12 In the United States, this framework is referred to as the nuclear command, control, and communications (NC3) system, which dictates the means through which authority is exercised and operational command and control of nuclear procedures are conducted.
However, a growing body of research has highlighted the potentially destabilizing consequences of integrating AI into NC3.3 This includes the following threat vectors:
- Increased Reliance on Inaccurate Information: AI systems have already displayed significant inaccuracy and inconsistency across a wide range of domains. As the relevant data that are needed for the training of AI systems for NC3 are extremely sparse – nuclear weapons have only been deployed twice in history, and were deployed in a substantially different nuclear landscape – AI systems are even more likely to exhibit error in these use cases than others. While there has been considerable focus on ensuring that there are ‘humans in the loop’ (i.e., the final decision is made by a human authority), this may prove to be challenging in practice. If an AI system claims that a nuclear weapon has been launched by an adversary, studies suggest it is unlikely that human agents would oppose this conclusion, regardless of its validity. This problem of ‘machine bias’ has already been demonstrated in other domains, making the problem of ensuring ‘meaningful human control’ over AI systems incredibly difficult.4
- Increased Reliance on Unverifiable Information: At present, it is nearly impossible to determine the exact means by which advanced AI systems reach their conclusions. This is because current means of ‘interpretibility’ – or understanding why AI systems behave the way they do – lag far behind the state-of-the-art systems themselves. In addition, because modern nuclear launch vehicles (e.g. intercontinental ballistic missiles (ICBMs), submarine-launched ballistic missile (SLBMs)) deliver payloads in a matter of minutes, it is unlikely there would be enough time to independently verify inferences, conclusions, and recommendations or decisions made by AI systems integrated in NC3.
- Artificial Escalation and General Loss of Control: If multiple nuclear powers integrate AI into nuclear decision-making, there is a risk of “artificial escalation.” Artificial escalation refers to a type of inadvertent escalation in which adversaries’ respective AI systems make calculations based on strategic maneuvers or information originating from other AI systems, rather than from human judgment, creating a positive feedback loop that continuously escalates conflict.5 Importantly, there is likely to be a dilution of human-control in these situations, as there would be incentives to rely on AI judgements in response to adversary states which are doing the same. For instance, if adversaries are presumed to be making military decisions at machine speeds, to avoid strategic disadvantage, military leaders are likely to yield increasing deference to decision-making and recommendations by advanced AI systems at the expense of meaningful human judgment. This leaves significantly less time for clear-headed communication and consideration, instead motivating first-strike, offensive actions with potentially catastrophic consequences.
#2. Expansion of Nuclear Arsenals and Escalation due to developments in Intelligence, Surveillance and Reconnaissance (ISR) capabilities
ISR refers to coordinated acquisition, processing, and dissemination of accurate, relevant, and timely information and intelligence to support military decision-making processes. The belief that other states do not have perfect information about their adversaries’ nuclear launch capabilities is essential to maintaining strategic deterrence and reducing insecurity, as it theoretically preserves second strike capabilities in the event of an attack, underscoring mutually-assured destruction. Toward this end, many nuclear powers, including Russia and China, employ mobile missile launchers because they are more difficult to track and target compared to stationary weapons systems. However, both actual and imagined developments in ISR resulting from AI integration increase the perceived threat of detection and preemptive attack on mobile missile launchers and other clandestine military technology. Should a competing nuclear power come to believe that an adversary possesses perfect information regarding the locations of nuclear weapons systems, the possibility that adversaries deploy their nuclear stockpiles rather than risk having them dismantled increases considerably. Such instability is prone to lead to expansion of nuclear arsenals, increased escalation on other fronts, and further risk of nuclear conflict.
#3 Increased Vulnerability of Nuclear Arsenals and Command Systems to Cyber Attacks
Advancements in artificial intelligence have led to rapid expansion in the capacity for malevolent actors to launch cyberattacks and exploit cyber-vulnerabilities.6 This includes significantly enhanced capabilities to exploit technical gaps in nuclear security infrastructure (e.g. zero-day vulnerabilities) and to manipulate high-value persons in positions of nuclear command and control (e.g. through deception or blackmail via phishing and spearphishing attacks). NATO allies have pointed out the threat of AI systems being used to attack critical infrastructure, and nuclear arsenals and command and control centers.7 In addition, if states move toward integrating AI into NC3 systems, such systems would be even more vulnerable to cyberattacks and data poisoning, a practice that entails manipulating the datasets AI systems are trained on to modify their behavior and exploit weaknesses. As data centers and systems are often networked, a cyber-failure could rapidly spread throughout the system, and damage other military command and control systems.
#4 Nuclear Escalation and Misperception due to AI-Generated Disinformation
Advanced AI systems have already displayed the capacity to generate vast amounts of compelling disinformation. This disinformation is generated in text using large language models, and via the synthetic construction of fake audiovisual content such as pictures and videos, also known as deep-fakes. Such disinformation is likely to have an outsized negative impact on military confrontation, and in particular on nuclear risk. For instance, if an artificially-engineered piece of audiovisual material is incredibly compelling and signals intended nuclear action, the immediacy of advanced missile technology (see #1B) would not provide sufficient time for vetting the authenticity of the information and may push decision-makers to default to a nuclear response.
Policy Recommendations
In light of the significant risks identified in the previous section, considerable attention from policymakers is necessary to ensure that the safety and security of the American people are not jeopardized. The following policy recommendations represent critical, targeted first steps to mitigating these risks:
- Limit use of AI Systems in NC3 and Establish Criteria for ‘Meaningful Human Control’: As recommended by a growing number of experts, the US should prohibit or place extremely stringent constraints the use of AI systems in the highest-risk domains of military decision-making. As discussed, mere human involvement at the tail-end of nuclear decision-making is unlikely to be effective in preventing escalation of nuclear risk from integration of AI systems. Minimizing the use of advanced AI systems where safer alternatives are available, requiring meaningful human control at each step in the decision-making process, and ensuring human understanding of decisionmaking criteria of any systems deployed in NC3, would reduce risks of accidental use and loss of human control, and would also provide crucial signals to geopolitical adversaries that would minimize undue escalation risk.
- Require Meaningful Hunan Control for All Potentially Lethal Conventional Weapon Use: Escalation to nuclear conflict does not occur solely within the nuclear domain, but rather emerges from broader geopolitical tensions and military maneuvers. Though this brief focuses specifically on the risks at the intersection of AI and NC3, incorporating AI into any military decision-making with major, irreversible consequences increases the risk of artificial escalation and loss of control that could eventually evolve into nuclear conflict. In order to reduce the risk of artificial escalation that could trigger nuclear conflict, the US should require by law that any potentially lethal military decision is subject to meaningful human control, regardless of whether it involves nuclear or conventional weapons systems. While the Department of Defense (DoD) Directive 3000.09 on Autonomy in Weapons Systems presently requires “appropriate levels of human judgment” in the use of force, this could be interpreted to allow for low levels of human judgment in some military operations, and is subject to change depending on DoD leadership. To ensure sound military decision-making that mitigates artificial escalation risk, “meaningful human control” should be codified in statute for any use of potentially-lethal force.
- Improve Status Quo Stability by Reducing Nuclear Ambiguities: The US should formally renounce first strikes – i.e., categorically state that it will not initiate a nuclear conflict – which would help assuage tensions, reduce the risk of escalation due to ambiguities or misunderstanding, and facilitate identification of seemingly inconsistent actions or intelligence that may not be authentic. Finally, the US should improve and expand its military crisis communications network, or ‘hotlines’, with adversary states, to allow for rapid leadership correspondence in times of crisis.
- Lead International Engagement and Standard-Setting: The US must adopt best practices for integration of AI into military decision-making, up to and potentially including recommending against such integration altogether at critical decision points, to exercise policy leadership on the international stage. In addition, the US should help strengthen the Nuclear Non-Proliferation Treaty and reinforce the norms underpinning the Treaty on the Prohibition of Nuclear Weapons in light of risks posed by AI.
- Adopt Stringent Procurement and Contracting Standards for Integration of AI into Military Functions: Because NC3 is not completely independent of broader military decision-making and the compromise or malfunction of other systems can feed into nuclear escalation, it is vital that stringent standards be established for procuring AI technology for military purposes. This should include rigorous auditing, red-teaming, and stress-testing of systems intended for military use prior to procurement.
- Fund Technical Research on AI Risk Management and NC3: The US should establish a risk management framework for the use of AI in NC3. Research in this regard can take place alongside extensive investigation of robust cybersecurity protocols and measures to identify disinformation. It should also include research into socio-technical mechanisms for mitigating artificial escalation risk (e.g. how to minimize machine bias, how to ensure that military decision-making happens at human speeds) as well as mechanisms for verifying the authenticity of intelligence and other information that could spur disinformation-based escalation. This would encourage the development of AI decision-support systems that are transparent and explainable, and subject to robust testing, evaluation, validation and verification (TEVV) protocols for specifically developed for AI in NC3. Such research could also reveal innovations in NC3 that do not rely on AI.
Finally, it is vital to set up an architecture for scrutiny and regulation of powerful AI systems more generally, including those developed and released by the private sector for civilian use. The nuclear risks posed by AI systems, such as those emerging from AI-enhanced disinformation and cyberwarfare, cannot be mitigated through policies at the intersection of the AI-nuclear frontier alone. The US must establish an auditing and licensing regime for advanced AI systems deployed in civilian domains that includes evaluation of risk for producing and proliferating widespread misinformation that could escalate geopolitical tensions, and risk of use for cyberattacks that could compromise military command control and decision support systems.
↩ 1 Horowitz, M. and Scharre, P. (December, 2019). A Stable Nuclear Future? The Impact of Autonomous Systems and Artificial Intelligence; Dr. James Johnson on How AI is Transforming Nuclear Deterrence. Nuclear Threat Initiative.
↩ 2 Reihner, P. and Wehesner, A. (Noveber, 2019). The real value of AI in Nuclear Command and Control. War on the Rocks.
↩ 3 Rautenbach, P. (February, 2023). Keeping humans in the loop is not enough to make AI safe for nuclear weapons. Bulletin of Atomic Scientists.
↩ 4 Baraniuk, S. (October, 2021). Why we place too much trust in machines. BBC News.
↩ 5 The short film “Artificial Escalation,” released by FLI in July 2023, provides a dramatized account of how this type of escalation can occur. This policy primer delves into mitigation strategies for the risks portrayed in the film.
↩ 6 These concerns are discussed in greater detail in “Cybersecurity and Artificial Intelligence: Problem Analysis and US Policy Recommendations“.
↩ 7 Vasquez, C. (May, 2023), Top US cyber official warns AI may be the ‘most powerful weapon of our time’. Cyberscoop; Artificial Intelligence in Digital Warfare: Introducing the Concept of the Cyberteammate. Cyber Defense Review. US Army.
Preventing Nuclear War through Storytelling
In an era shadowed by the Cold War’s persistent dread, two films resonated powerfully with the public and world leaders. The 2023 Future of Life Award honors the visionaries behind these narratives: Walter F. Parkes and Larry Lasker are behind the riveting techno-thriller “WarGames,” while the groundbreaking television event “The Day After” comes from the visionary Brandon Stoddard, with Edward Hume as the screenwriter and Nicholas Meyer as the director.
Winners – WarGames
US Release: June 3, 1983

Winners – The Day After
US Release: November 20, 1983

Released in the tension-filled year of 1983, these films not only reflected the era’s nuclear anxieties but also played a direct role in shaping policy. They went beyond mere entertainment, acting as significant catalysts for dialogue. These films influenced policymakers and raised public awareness about the grave risks associated with nuclear warfare, leading to tangible, preventative action from leaders.
Witness how their creative vision transcended the silver screen to safeguard the future of our world, as we celebrate their achievement with a video tribute to the 2023 Future of Life Award recipients.
Press release
Creators of “WarGames” and “The Day After” Win Award For Helping to Prevent Nuclear War
For Immediate Release
LOS ANGELES, November 13: The 2023 Future of Life Award celebrates Walter Parkes and Larry Lasker, screenwriters of techno-thriller WarGames, and Brandon Stoddard, visionary behind groundbreaking television film The Day After, along with screenwriter Edward Hume and director Nicholas Meyer. Forty years after their release, the award recognises how these films shifted narratives, boosted awareness around nuclear war and the threat of escalation, and even led to preventative action from leaders. These filmmakers made the world a safer place.
The Future of Life Institute (FLI), who present the award, have produced a short film about the films and their impact. Both released in 1983, they reflect growing tensions between the United States and USSR and widespread, existential fears that accompanied them. With their contrasting styles, both films played a profound role in reducing the threat of nuclear war, and serve as standout demonstrations of how different storytelling approaches can illustrate global issues and inspire action. Watching WarGames prompted President Reagan to explore the United States’ own cyber vulnerabilities when it came to defence and nuclear weapons, and to issue the first ever Presidential Directive on computer security 18 months later. Writer Walter Parkes explains:
“WarGames began as a character story about a precocious kid’s journey to a mentor, a brilliant, self-exiled scientist in need of a successor – but it was our own journey as writers which led us to the undeniable truth about the existential threat posed by nuclear weapons. We’re humbled and gratified that the movie and its underlying message – that for certain games, “the only winning move is not to play” – continues to resonate, and that the Future of Life Institute would acknowledge us for our work.”
The original broadcast of The Day After (November 20, 1983) was watched by more than one hundred million Americans. This unprecedented television event reignited non-proliferation debates and galvanised support for disarmament. Reagan’s memoirs An American Life reveal that the film changed his mind about nuclear policy, leading him to sign the Intermediate-Range Nuclear Forces Treaty in 1987, which significantly reduced Cold War nuclear arsenals. Director Nicholas Meyer remarks:
“Timing turns out to be everything. The Day After arrived at a confluence of culture, politics, policy and technology, uniquely positioning it to exert an outsize influence, which in turn allowed it to focus the world’s attention for an instant on the single most urgent topic: Earth’s survival. Such a confluence may never occur again…The line between altruism and selfishness is sometimes very thin. I made The Day After not only as a matter of altruism and principle, but also of simple selfishness. As a father, I felt – and still feel – that the survival of Earth is in my own best interests. And everyone else’s.”
The Future of Life Award honours individuals who, without having received much recognition at the time of their achievements, helped make today’s world dramatically better than it might otherwise have been. Director of FLI Futures Emilia Javorsky writes:
“These films and their creators showcase the profound role that storytellers can play in tackling some of our world’s most intractable and extreme threats. They serve as a leading example of how artists can help make the world safer by examining urgent issues in compelling and evocative ways, and in turn inspire our leaders to step up and take action. FLI is honored to celebrate them today.”
Featured on StarTalk Podcast
Hear the Future of Life Award 2023 featuring on this StarTalk podcast episode:
In the media
The story of these films and their impact on the world has been celebrated in other outlets in honour of the 40th anniversary of their release:
- CNN, How ‘The Day After’ brought Americans together – and helped end the Cold War, 17th Nov
- LA Times, The three filmmakers who saved the world, 20th Nov
Find out more
Below are some other resources related to the topic of the 2023 Future of Life Award:
- Apocalypse Television: How The Day After Helped End the Cold War – Book by Craig David.
- Artificial Escalation – What would happen if AI were integrated into today’s nuclear command and control systems?
- How would a nuclear war between the USA and Russia affect you personally? – How bad would it be if there was a nuclear war between the USA and Russia today?
- Imagine A World Podcast – Our recent podcast ‘Imagine A World’ envisions a positive future with AI.